Not long ago Brandon, a reputable headhunter from UK, asked me point-blank: “Do you know Rust?” Well, since 1993 I’ve written code in BASIC, CLIPPER, PASCAL, SQL, C, PostScript (yes, the stack-oriented beast), TEX, Intel and MIPS assembly, PHP, Java, Matlab, R, Julia, Maple, Maxima, Fortran, C#, Go, Ruby, grammar parsers like LEX and YACC, then of course JavaScript and Python — and my personal favourite: C++ metaprogramming. In other words: if it’s Turing-complete and vaguely hostile to human beings, chances are I’ve built something in it. So no, it’s not the language that matters, it’s the craft. But since Rust is today’s poster child for systems programming, I wrote IEX-DOWNLOAD entirely in Rust. My way of saying: sure, I can do that too, and I’ll even enjoy the borrow checker while I’m at it.
Key Differences (TOPS vs DEEP vs DEEP+)
Feature
TOPS (Top-of-book)
DEEP (Aggregated)
DEEP+ (Order-by-order)
Order granularity
Only best bid/ask + last trade
Aggregated by price level (size summed)
Individual orders (each displayed order)
OrderID / update per order
Not present
Not present
Present
Hidden / non-display / reserve portions
Not shown
Not shown
Not shown
Memory / bandwidth load
Lowest (very compact, minimal updates)
Lower (fewer messages, coarser updates)
Higher (tracking many individual orders, cancels, modifications)
Because it lets you grab over 13 TB of IEX tick data in one shot. Wait, wasn’t it 6 TB last week? Exactly. Trading data is like an iceberg: TOPS shows you the shiny tip (best bid/ask and last trade), while the real bulk is hidden underneath in DEEP and DEEP+. That’s where the weight lives — and where the fun begins.
Progress bar with attitude → because watching terabytes flow should feel satisfying.
PEG-based date parser → type 2025-01-?? or 202{4,5}-{04,05}-?? and it just works, no regex headaches.
One tiny ELF → a single 3.5 MB executable (-rwxrwxr-x 2 steven steven 3.5M Sep 23 11:00 target/release/iex-download).
No Python venvs, no dependency jungles. Drop it anywhere, chmod +x, and let it rip.
DEEP → richer, aggregated depth (enough for most analytics).
DEEP+ (DPLS) → the full microstructure playground (every displayed order).
And that’s the trick: IEX-DOWNLOAD gets you the firehose, and IEX2H5
turns that torrent into tidy, high-performance HDF5 files.
So there you have it: IEX-DOWNLOAD, 4,597 files and 13.26 TB of market microstructure, distilled into a 3.5 MB Rust binary. And to Brandon — thank you for asking the right question. Sometimes all it takes is a good headhunter’s nudge to turn an idea into a tool. Rust may be the new kid, but in the right hands it can move mountains… or at least download a few terabytes before lunch.
It started with a glitch. Buried deep in a mountain of tick data, a whole week suddenly collapsed into the twilight zone of December 31, 1969, 23:59:59 — one second before the Unix epoch. The ghost date. You get it when a timestamp is filled with all ones (0xFFFFFFFFFFFFFFFF): a value that looks legitimate to the computer but really means “no timestamp at all.” At first I chalked it up as a curious terminal artifact, the kind of oddity you see once and forget. But then the implications sank in. This phantom week explained why my list of the 30 Most Consistently Traded Stocks on IEX mysteriously came up short — barely 800 trading days of history where there should have been many more.
To rewind a bit: Sander, George, and I go back over a decade, long before “AI” was splashed across every headline. Back then, stock data was either prohibitively expensive or painfully DIY, with traders like our friend Mike cobbling together custom recorders in C# just to peek at the order book. Fast forward to today: IEX generously streams its ticks to the world, and tools like IEX2H5 can compress terabytes into tidy HDF5 stores.
So why bring up old friends? Because not long ago Sander showed up with a 4 TB hard drive in hand, asking me to copy over a slice of the 6 TB top-of-book PCAP dataset. I told him I could do better by repacking the PCAP frames into HDF5 chunks, which shrank it neatly to 2 TB — but this story isn’t about compression. It’s about spotting a streak of market events stamped in 1969, and how a late-night debugging session showed the culprit wasn’t a bug in my code at all, but an undocumented feature of the IEX feed itself.
A subtle quirk, yes — but also a reminder that in high-frequency systems, nothing is ever as simple as it looks.
So when I started converting PCAP datasets into HDF5 chunks, I expected nothing more dramatic than a progress bar slowly marching forward. Instead, buried among terabytes of perfectly normal ticks, I stumbled on something strange — a whole week of market activity that seemed to vanish into thin air. That discovery set the stage for what turned into a late-night debugging session worthy of a detective novel.
At first, I thought it was my code. I tore apart the PCAP and PCAP NG parsers, double-checked my math, and even second-guessed whether I’d miscompiled with the wrong flags. But then came the smoking gun: Wireshark showed me that those packets weren’t malformed at all. They carried a timestamp field set to 0xffffffffffffffff.
That was the lightbulb moment. This wasn’t a bug in my PCAP parser—it was an undocumented feature in the IEX feed itself: a sentinel value marking “invalid” packets. The kind of thing no spec sheet, no glossy API doc, and no vendor tutorial will ever tell you.
template<typenameconsumer_t>structtransport_t{[...]voidtransport_handler(constiex::transport::header*segment){if(segment->time==(~0ULL))return;// 0xffffffffffffffffULL denotes invalid packet see issue #93if(!count)today=date::floor<date::days>(time_point(duration(segment->time)));autonow=time_point(duration(segment->time));// trigger opening market eventif(now>today+this->start&&!is_market_opened)[...]if(is_market_opened&&!is_market_closed)[...]count++;}voidend(){if(this->is_market_opened&&!this->is_market_closed)[...]}[...]longcount=0;/*!< Number of transport segments processed */}
Simple enough—once you know what you’re looking for. But let’s be honest: it’s the kind of thing that’s easy to miss. Many would have written it off as a glitch in the HDF5 backend, a flaky ETL job, or even blamed the exchange. Meanwhile, those “clean” datasets would be quietly dropping days, nudging strategies off balance, and planting landmines that only go off weeks later in backtests or production. These are the kinds of ghosts you only learn to spot after years in the trenches—when you’ve seen enough undocumented quirks, corner cases, and phantom packets to know they’re always lurking just out of sight.
Forensic Debugging: When 0xFFFFFFFFFFFFFFFF Strikes Step 1: The Phantom Week Appears
This is the point where the 1969 timestamps first appear in the output. With over 2,200 files in play, it’s easy to overlook the anomaly.
To make sure the parser wasn’t getting creative with timestamps, I resorted to the pinnacle of debugging science: printing values exactly where they matter
And lo and behold: tshark confirmed it wasn’t my imagination — the raw frames in the failing files kicked off with a string of ffffffffffffffff. A pattern nowhere to be found in the IEX spec, but clear enough to scream ‘here be undocumented features.
So I dove back into the IEX2H5 code and revisited the timestamp parsing with the most advanced debugging technique ever invented: printf. And what do you know — the mysterious ffffffffffffffffs were right there, just as the packets promised. Sometimes the old ways are still the best.
And the fix? A $1000 single-liner: just skip ~0ULL as an undocumented sentinel. Of course, the code change is trivial — the real work was chasing the phantom through terabytes of ticks, hex dumps, and Wireshark traces
So here’s the moral of the story: If you’re serious about market data—if your trading desk, quant research, or risk analytics depends on every tick being correct—you don’t want to leave it to chance. You don’t want to find out six months from now that your backtests were running on phantom trades. Because in high-frequency trading, it’s never “just one bug.” It’s always the one you don’t see coming—the one that makes your million-dollar strategy look like it’s trading in 1969.
namespaceiex::pcap{structglobal_header_t{uint32_tmagic_number;/*!< Magic number used to detect byte order and timestamp resolution */uint16_tversion_major;/*!< Major version number (typically 2) */uint16_tversion_minor;/*!< Minor version number (typically 4) */int32_tthiszone;/*!< GMT to local time correction (usually zero) */uint32_tsigfigs;/*!< Accuracy of timestamps (not used) */uint32_tsnaplen;/*!< Max length of captured packets, in octets */uint32_tnetwork;/*!< Data link type (1 = Ethernet) */}__attribute__((packed));structpacket_header_t{uint32_tts;/**< Timestamp: seconds since Unix epoch */uint32_tns;/**< Timestamp: sub-second precision (micro or nanoseconds) */uint32_tcaptured;/**< Number of bytes actually captured (≤ snaplen) */uint32_toriginal;/**< Original length of the packet on the wire */}__attribute__((packed));template<classstream,classconsumer>structproducer_t:publicbase::producer_t<stream,consumer>{usingparent=base::producer_t<stream,consumer>;usingduration=typenameconsumer::duration;usingparent::needs_byte_swap,parent::read_exact,parent::buffer,parent::is_little_endian,parent::packet_count,parent::link_type,parent::version_major,parent::version_minor,parent::snap_length,parent::check_compatibility;explicitproducer_t(FILE*fd,durationhb):parent(fd,hb){read_exact(reinterpret_cast<uint8_t*>(&global_header),sizeof(global_header));if(!utils::pcap::is_valid_magic(global_header.magic_number))THROW_RUNTIME_ERROR("Invalid PCAP magic number: "+std::to_string(global_header.magic_number));this->needs_byte_swap=utils::pcap::needs_byteswap(global_header.magic_number);if(this->needs_byte_swap){global_header.version_major=std::byteswap(global_header.version_major);global_header.version_minor=std::byteswap(global_header.version_minor);global_header.thiszone=std::byteswap(global_header.thiszone);global_header.sigfigs=std::byteswap(global_header.sigfigs);global_header.snaplen=std::byteswap(global_header.snaplen);global_header.network=std::byteswap(global_header.network);}link_type=static_cast<utils::pcap::link_type>(global_header.network);version_major=global_header.version_major,version_minor=global_header.version_minor,snap_length=global_header.snaplen,is_little_endian=utils::pcap::is_little_endian(global_header.magic_number);check_compatibility("pcap");}voidrun_impl(){while(read_exact(reinterpret_cast<uint8_t*>(&packet_header),sizeof(packet_header))){if(packet_header.captured>buffer.size())THROW_RUNTIME_ERROR("packet too large: "+std::to_string(packet_header.captured)+" buffer: "+std::to_string(buffer.size()));if(!read_exact(buffer.data(),packet_header.captured))break;// EOFconstiex::transport::header*segment=reinterpret_cast<constiex::transport::header*>(buffer.data()+sizeof(iex::base::packet));this->transport_handler(segment);packet_count++;}this->end();}global_header_tglobal_header{};/*!< parsed PCAP global header */packet_header_tpacket_header{};/*!< current PCAP packet header */};}// namespace iex::pcap
What if you could replay the last 9 years of market activity — every quote, every trade — and figure out which stocks have never left the party?
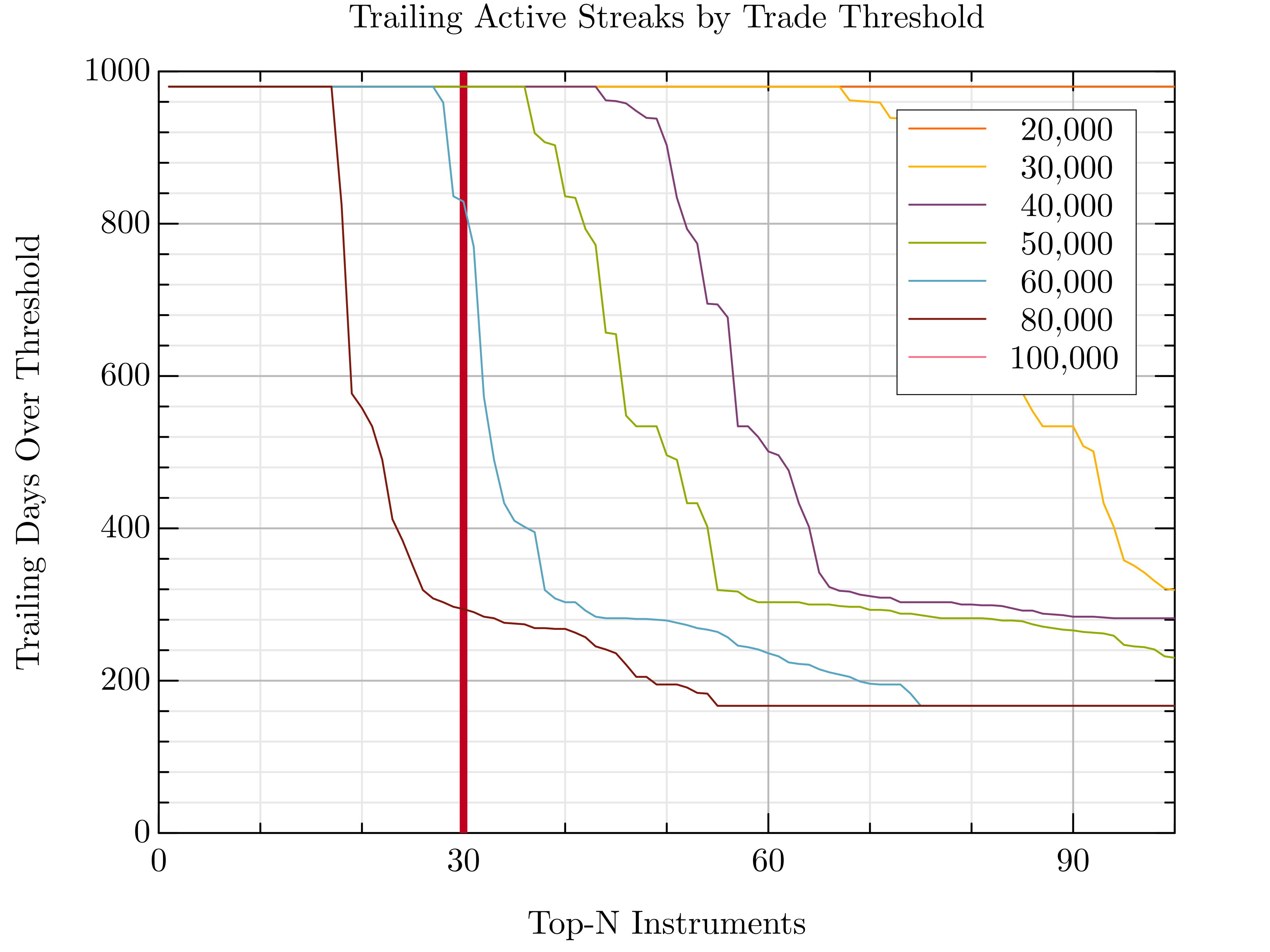
Last Friday, a quiet challenge came up in a conversation. Someone with a sharp mathematical mind and a preference for staying behind the scenes posed a deceptively simple question: "Which stocks have been traded the most, consistently, from 2016 to today?"That one question sent me down a 27-hour rabbit hole…
We had the data: 6TB of IEX tick captures spanning 2'187 PCAP files and over 22'119 unique symbols. We had the tools: an HDF5-backed firehose built for high-frequency analytics in pure C++23.
What followed was a misadventure in semantics. I first averaged trade counts across all dates — a rookie mistake. Turns out, averaging doesn’t guarantee consistency — some stocks burn bright for a while, then disappear. That oversight cost me half a day of CPU time and a good chunk of humility.
The fix? A better idea: walk backwards from today and look for the longest uninterrupted streak of trading activity for each stock.
Luckily, the 12 hours spent building the index weren’t wasted — that heavy lifting could be recycled for the new logic.
Implementation time? 30 minutes. Execution time? 5 seconds. Victory? Priceless.
Before we can rank stocks, we need summary statistics from the raw IEX market data feeds. That’s where iex2h5 comes in — a high-performance HDF5-based data converter purpose-built for handling PCAP dumps from IEX.
To extract stats only (and skip writing any tick data), we use the --command none mode. We'll name the output file something meaningful like statistics.h5, and pass in a file glob — the glorious Unix-era invention (from B at Bell Labs) — pointing to our compressed dataset, e.g. /lake/iex/tops/*.pcap.gz.
Of course, we’re all lazy, so let’s use the short forms -c, -o, and let iex2h5 do its thing:
/trading_days → the full trading calendar (2,187 days)
/stats → per-symbol statistics across all days (e.g. trade volume, trade count, first/last seen)
On the performance side:
Raw storage throughput (ZFS): ~254 MB/s
End-to-end pipeline throughput: 5.76 TB of compressed PCAP input in 44,087 s → ~130 MB/s effective
Event rate: ~5.9 million ticks/sec sustained
From here you’re ready to rank, filter, and extract the top performers. The best part? A full 6 TB dataset was processed in ~12 hours — on a single desktop workstation, using a single-threaded execution model. No cluster, no parallel jobs.
These results form a solid baseline: the upcoming commercial version will extend the engine to a multi-process, multi-threaded execution model, scaling performance well beyond what a single core can deliver.
Step 2 — digest the statistics Top-K Trade Streak Filter for Julia
#!/usr/bin/env python3importnumpyasnpimporth5pyfrompathlibimportPathbase=Path.home()/"scratch"input_file=base/"index.h5"output_file=base/"top30.h5"cutoff_limit,lower_bound=30,50_000fd=h5py.File(input_file,"r",swmr=True)deftrailing_streak(x:np.ndarray,min_val:float)->int:cnt=0forvinx[::-1]:ifv>min_val:cnt+=1else:breakreturncntdates=fd["/trading_days.txt"][:].astype(str)instruments=fd["/instruments.txt"][:].astype(str)D,I=len(dates),len(instruments)A=np.zeros((D,I),dtype=np.float64)forday,dateinenumerate(dates):path=f"/stats/{date}/trade_size"ifpathinfd:count=np.asarray(fd[path][()]).ravel()n=min(I,count.size)A[day,:n]=count[:n]# Step 2: Compute trailing streak length for each instrumentstreak_lengths=np.array([trailing_streak(A[:,i],lower_bound)foriinrange(A.shape[1])])# Step 3: Rank instruments by streak length# DO NOT USE: it is not a stable sort, will diverge from julia implementation# order = np.argsort(-streak_lengths) order=np.lexsort((np.arange(len(streak_lengths)),-streak_lengths))selection=order[:cutoff_limit]h5_instruments=instruments[selection]h5_trading_days=dates[-streak_lengths[selection].min():]# Step 4: write resultstr_dtype=h5py.string_dtype(encoding="utf-8")withh5py.File(output_file,"w")asfd_out:fd_out.create_dataset("/instruments.txt",data=h5_instruments.astype(object),dtype=str_dtype)fd_out.create_dataset("/trading_days.txt",data=h5_trading_days.astype(object),dtype=str_dtype)
usingPrintf,FormatimportGRUtils:oplot,plot,legend,xlabel,ylabel,title,savefigcolorscheme("solarized light")thresholds=[20_000,30_000,40_000,50_000,60_000,80_000,100_000]cutoff_limit,max=30,100compute_streaks(A,min_val)=[trailing_streak(A[:,i],min_val)foriin1:size(A,2)]sorted_streaks_per_threshold=Dict()fortinthresholdsstreaks=compute_streaks(A,t)sorted_streaks_per_threshold[t]=sort(streaks,rev=true)[1:max]endplot([cutoff_limit,cutoff_limit],[0,1000],"-r";linewidth=4,linestyle=:dash,xlim=(0,max),xticks=(10,3),label=" 30")fortinthresholds[1:end]oplot(1:length(sorted_streaks_per_threshold[t]),sorted_streaks_per_threshold[t];label=format("{:>8}",format(t,commas=true)),lw=2)endlegend("")xlabel("Top-N Instruments")ylabel("Trailing Days Over Threshold")title("Trailing Active Streaks by Trade Threshold")
Step 3 — Reprocess the Tick Data for the Top 30 Stocks
Now that we’ve identified the most consistently active stocks, it’s time to zoom in and reprocess just the relevant PCAP files. If you already have tick-level HDF5 output, you’re set. But if not, here's a neat trick: use good old Unix GLOB patterns to cherry-pick just the days you need — no need to touch all 6TB again.
For example, let’s reconstruct a trading window around September 2021:
iex2h5-cirts-otop30.h5/lake/iex/tops/TOPS-2021-09-1{3,4,5,6,7,8,9}.pcap.gz# fractional startiex2h5-cirts-otop30.h5/lake/iex/tops/TOPS-2021-09-{2,3}?.pcap.gz# rest of the month
And then stitch together additional months or years:
These globs target specific slices of the timeline while keeping file-level parallelism open for future optimization. And of course, you can always batch them via xargs.
As this series of experiments suggests, there’s more to large-scale market data processing than meets the eye. It’s tempting to think of backtesting as a clean, deterministic pipeline — but in practice, the data fights back.
You’ll encounter missing or corrupted captures, incomplete trading days, symbols that appear midstream, and others that vanish without warning. Stocks get halted, merged, delisted, or IPO mid-cycle — all of which silently affect continuity, volume, and strategy logic.
Even more subtly, corporate actions like stock splits can distort price series unless explicitly accounted for. For example, Nvidia’s 10-for-1 stock split on June 7, 2024, caused a sudden drop in share price purely due to adjustment — not market dynamics. Without proper normalization, strategies can misinterpret these events as volatility or crashes.
Even a simple idea like “find the most consistently traded stocks” turns out to depend on how you define consistency, and how well you understand the structure of your own dataset.
Problem: Compact, Order-Preserving Identifiers for Short Symbols
In domains like high-frequency trading, structured storage, or financial indexing, identifiers such as stock symbols (e.g., "AAPL", "GOOG", "TSLA") are:
Short — typically ≤ 8 characters
Drawn from a small alphabet — ~32 to 40 printable characters
Compared lexicographically — e.g., "ABC" < "XYZ" must hold
These structural constraints can be exploited to encode each symbol into a compact, fixed-width binary key while preserving their natural sort order.
Specifically, such systems often need:
Lexicographic ordering — to maintain sorted maps, symbol trees, or search indices
Fixed-size keys — for CPU- and cache-friendly performance
Support for variable-length symbols — without breaking ordering
Ability to pack extra metadata — like 16-bit contract IDs or timestamps
But typical representations fall short:
std::string / char[] are variable-length and inefficient as keys
strcmp is slow, branching, and non-SIMD friendly
Standard Base64 isn't order-preserving
Hashes destroy ordering and increase collision risk
➤ Radix64 encoding solves this by leveraging the symbol structure — short, constrained, ordered strings — to pack lex-order-preserving representations into just 64 bits.
Solution: Order-Preserving Radix64 Encoding
Radix64 solves this by:
Encoding up to 8 characters as a 48-bit big-endian base-64 integer
Padding shorter strings with the lowest code to preserve prefix order
Optionally combining a 16-bit integer (e.g., contract ID) in the LSBs
Making unsigned integer comparison exactly match lexicographic order
So you can now represent things like:
"AAPL" → 48-bit radix64 prefix
contract → 16-bit index
key → 64-bit sortable, compact ID
ECDSA operates on elliptic curve groups over finite fields.
In the most common form, the curve is defined by the Weierstrass equation:\(E(\mathbb{F}_p):\; y^2 \equiv x^3 + ax + b \pmod p,\) where \(a, b\) are curve parameters and \(p\) is a prime defining the field \(\mathbb{F}_p\). In production systems, the curve is fixed by cryptographers — for example, secp256k1 in Ethereum — but nothing prevents you from experimenting with your own, especially for learning, prototyping, or testing with small primes.
Generate a toy Weierstrass curve
This example searches for a curve over primes \(\pi \in (97,103)\), with parameters \(a \in (10,15)\), \(b \in (2,7)\). It selects the first candidate that is non-singular, whose group of points has prime order, and that admits a generator spanning the group.
Here, \(q\) is the order of the generator \(\mathbb{G} (0𝔽₉₇,10𝔽₉₇)\), \(h\) the cofactor, and \(\#E = q \cdot h\) the total number of points on the curve.
Sign a Message (ECDSA)
priv,pub=genkey(curve)# Generate private/public key pairmsg="hello ethereum"# The message to signsignature=sign(curve,priv,msg)# → (r, s, v)
The result is a NamedTuple:
(r=...,s=...,v=...)
Here, \((r,s)\) are the ECDSA signature scalars, and \(v\) is the recovery identifier — letting you reconstruct the signer’s public key from the signature and message alone. This is exactly how Ethereum transactions prove authenticity without revealing the private key.
Verification checks that the signature \((r,s)\) was produced with the private key corresponding to the public key pub, on the exact message msg. If the check passes, you know the message is authentic and unaltered — the essence of digital signatures in action.
ECDSA with recovery adds a small extra bit \(v\) to the signature, making it possible to reconstruct the signer’s public key directly from (msg, signature). This is how Ethereum avoids shipping full public keys inside every transaction: the network can derive them on the fly, saving space while still proving who signed what.
Summary
TinyCrypto.jl makes it easy to:
Define toy elliptic curves over small prime fields
Generate key pairs and sign messages with ECDSA
Verify signatures to ensure authenticity and integrity
Recover public keys from signatures (à la Ethereum)
Perfect for learning, prototyping, or experimenting with elliptic curve cryptography — without the overhead of production-grade libraries.
Rudresh shared that attempts to extend a dataset were failing with crashes or no effect—despite calling .extend(...) or H5Dextend(). Their code was creating a 2D dataset of variable‑length strings, but had not enabled chunking or specified unlimited max dimensions, leaving them stuck.
The Insight
If you don’t create a dataset with chunked layout and max dimensions set to unlimited (H5S_UNLIMITED), HDF5 creates it with contiguous storage and a fixed size that cannot be extended later. That's the crux: without chunking and unlimited dims, calling .extend will fail or crash.
A Possible H5CPP Solution
Here’s how you can cleanly create an extendible dataset and append to it—using H5CPP:
#include<h5cpp/all>intmain(){// Create a new file and an extendible dataset of scalar valuesh5::fd_tfd=h5::create("example.h5",H5F_ACC_TRUNC);// Create a packet-table (extendible) dataset of scalarsh5::pt_tpt=h5::create<size_t>(fd,"stream of scalars",h5::max_dims{H5S_UNLIMITED});// Append values dynamicallyfor(autovalue:{1,2,3,4,5}){h5::append(pt,value);}}
For a frame‑by‑frame stream (e.g., matrices or images):
#include<h5cpp/all>#include<armadillo>intmain(){h5::fd_tfd=h5::create("example.h5",H5F_ACC_TRUNC);size_tnrows=2,ncols=5,nframes=3;autopt=h5::create<double>(fd,"stream of matrices",h5::max_dims{H5S_UNLIMITED,nrows,ncols},h5::chunk{1,nrows,ncols});arma::matM(nrows,ncols);for(inti=0;i<nframes;++i){h5::append(pt,M);}}
Why This Works
Aspect
H5CPP Approach
Extendible storage
h5::max_dims{H5S_UNLIMITED}
Chunked layout setup
Automatic via h5::chunk{...}
Appending data
One-liners with h5::append(...)
Clean C++ modern API
Templates, RAII, zero boilerplate
TLDR
If your HDF5 dataset “can’t extend,” the culprit is almost always that it's not chunked with unlimited dimensions. Fix that creation pattern—chunking is mandatory.
With H5CPP, appending becomes elegant and idiomatic:
Create: h5::create with unlimited dims
Append: h5::append(...) in plain C++ style
Let me know if you'd like this turned into a tutorial or compared to the raw HDF5 C++ API equivalent.
Reading “all rows but a few fields” from hundreds-wide compound datasets can crush performance, especially in Python.
The fix? Restructure your HDF5 layout to align with real query behavior—use chunked blocks that contain all frequently accessed fields together. H5CPP supports this cleanly with a modern template-based API.
A user observed that writing huge blocks (≥10 GB) with HDF5 was noticeably slower than equivalent raw writes. Understandably—they're comparing structured I/O to unadorned write() calls. The question: is this performance gap unavoidable, or can HDF5 be tuned to catch up?
Here’s what I discovered—and benchmarked—on my Lenovo X1 running a recent Linux setup:
Running a cross‑product H5CPP benchmark, I consistently hit about 70–95% of the raw file system’s throughput when writing large blocks—clear evidence HDF5 is not inherently slow at scale.
With tiny or fragmented writes, overhead becomes a bigger issue—as Gerd already pointed out, direct chunk I/O is the key to performance there. Rebuild your own packer or write path around full chunks.
Or, if you want simplicity with speed, use H5CPP’s h5::append(). It streamlines buffered I/O, chunk alignment, and high throughput without manual hackery.
intmain(intargc,constchar**argv){size_tmax_size=*std::max_element(record_size.begin(),record_size.end());h5::fd_tfd=h5::create("h5cpp.h5",H5F_ACC_TRUNC);autostrings=h5::utils::get_test_data<std::string>(max_size,10,sizeof(fl_string_t));std::vector<char[sizeof(fl_string_t)]>data(strings.size());for(size_ti=0;i<data.size();i++)strncpy(data[i],strings[i].data(),sizeof(fl_string_t));// set the transfer size for each batchstd::vector<size_t>transfer_size;for(autoi:record_size)transfer_size.push_back(i*sizeof(fl_string_t));//use H5CPP modify VL type to fixed lengthh5::dt_t<fl_string_t>dt{H5Tcreate(H5T_STRING,sizeof(fl_string_t))};H5Tset_cset(dt,H5T_CSET_UTF8);std::vector<h5::ds_t>ds;// create separate dataset for each batchfor(autosize:record_size)ds.push_back(h5::create<fl_string_t>(fd,fmt::format("fixe length string CAPI-{:010d}",size),chunk_size,h5::current_dims{size},dt));// EXPERIMENT: arguments, including lambda function may be passed in arbitrary orderbh::throughput(bh::name{"fixed length string CAPI"},record_size,warmup,sample,[&](size_tidx,size_tsize_)->double{hsize_tsize=size_;// memory spaceh5::sp_tmem_space{H5Screate_simple(1,&size,nullptr)};H5Sselect_all(mem_space);// file spaceh5::sp_tfile_space{H5Dget_space(ds[idx])};H5Sselect_all(file_space);// IO callH5Dwrite(ds[idx],dt,mem_space,file_space,H5P_DEFAULT,data.data());returntransfer_size[idx];});}
So, large writes are nearly as fast as raw file writes. The performance dip is most pronounced with smaller payloads.
The OP wanted to bypass copying and buffering in memory by writing HDF5 chunks in parts—i.e., building them incrementally. They’d heard of using H5Dget_chunk_info plus pwrite() to patch up chunk contents manually, especially in uncompressed scenarios.
Let me clarify the constraints first: a chunk is an indivisible IO unit in HDF5. It is processed as a single atomic job—particularly vital if filters or compression are applied. That’s baked into the library semantics and reflects how most storage and memory subsystems work.
Here’s how you'd typically handle data in that model:
Chunk-based pipeline (e.g., with block ciphers):
1. pread(fd, data, full_chunk_size, offset)
2. Repeat until the entire chunk is loaded (must be whole)
3. Apply filters/pipelines to the chunk
4. Write or process…
Given this model, partial chunk writes simply don’t make sense—and won’t be accepted by HDF5’s filter chain integrity checks.
Read the entire chunk, decode it, process your changes, then write the full chunk back. It’s the only correct way.
If naive, direct chunk operations hit 90%+ of NVMe bandwidth in benchmarks, you're already in a sweet spot—focus on optimizing higher-level logic.
H5CPP’s h5::packet_table elevates this approach: it abstracts buffer management and chunk alignment, so you can safely accumulate data from multiple sources and efficiently flush complete chunks.
h5::packet_table handles pre-buffering and alignment
Fragment writes
Not supported
Use full chunk replacement workflow
Performance on NVMe
Good if chunked properly
Fine-tuned by h5::append() internals
Let me know if you'd like a code breakdown of h5::packet_table or a deep dive on how to handle chunk durability and concurrency in a streaming pipeline.
You’re working in a system that ingests data from multiple queues or streams, and you want to aggregate and flush them into HDF5 chunks incrementally. Essentially you need fine control: pack incoming data, apply filters, and write out only full chunks—or directly stream partial ones—without sacrificing alignment or performance.
See h5cpp::packet_table on GitHub—it's designed for chunked, appendable writes. It features a chunk-packing mechanism and a filter-chain you can adapt for your needs. I even slipped in an alignment bug (huge respect to Bin Dong at Berkeley for spotting it)—you’ll only run into it if your chunks aren’t properly aligned.
You should be able to modify h5::append so that it aggregates data from different queues and flushes when chunks are full. For inspiration, check the repository example that demonstrates how to use lock‑free queues and ZeroMQ with both C++ and Fortran.
 Last Friday, a quiet challenge came up in a conversation. Someone with a sharp mathematical mind and a preference for staying behind the scenes posed a deceptively simple question: "Which stocks have been traded the most, consistently, from 2016 to today?"
That one question sent me down a 27-hour rabbit hole…
Last Friday, a quiet challenge came up in a conversation. Someone with a sharp mathematical mind and a preference for staying behind the scenes posed a deceptively simple question: "Which stocks have been traded the most, consistently, from 2016 to today?"
That one question sent me down a 27-hour rabbit hole… As this series of experiments suggests, there’s more to large-scale market data processing than meets the eye. It’s tempting to think of backtesting as a clean, deterministic pipeline — but in practice, the data fights back.
You’ll encounter missing or corrupted captures, incomplete trading days, symbols that appear midstream, and others that vanish without warning. Stocks get halted, merged, delisted, or IPO mid-cycle — all of which silently affect continuity, volume, and strategy logic.
Even more subtly, corporate actions like stock splits can distort price series unless explicitly accounted for. For example, Nvidia’s 10-for-1 stock split on June 7, 2024, caused a sudden drop in share price purely due to adjustment — not market dynamics. Without proper normalization, strategies can misinterpret these events as volatility or crashes.
Even a simple idea like “find the most consistently traded stocks” turns out to depend on how you define consistency, and how well you understand the structure of your own dataset.
As this series of experiments suggests, there’s more to large-scale market data processing than meets the eye. It’s tempting to think of backtesting as a clean, deterministic pipeline — but in practice, the data fights back.
You’ll encounter missing or corrupted captures, incomplete trading days, symbols that appear midstream, and others that vanish without warning. Stocks get halted, merged, delisted, or IPO mid-cycle — all of which silently affect continuity, volume, and strategy logic.
Even more subtly, corporate actions like stock splits can distort price series unless explicitly accounted for. For example, Nvidia’s 10-for-1 stock split on June 7, 2024, caused a sudden drop in share price purely due to adjustment — not market dynamics. Without proper normalization, strategies can misinterpret these events as volatility or crashes.
Even a simple idea like “find the most consistently traded stocks” turns out to depend on how you define consistency, and how well you understand the structure of your own dataset.